It was a sad reality check to read Rachel Nolan's review of two books on U.S./Mexican border dynamics in a recent LRB. The fundamental reality is U.S. firearms freely flow into Mexico while drugs flow the opposite direction. Reducing crime and violence in Mexico would require the U.S. to meaningfully reform both the lousy state of public health and the abysmal state of firearms access.
However, this seems impossible when even the agency tasked with enforcement has both hands tied behind its back in a truly absurd manner:
The ATF is not legally permitted to keep a searchable digital database of gun sales, thanks to hysteria that ‘the government will come to take our guns,’ so they only have printouts. When a crime is called in and the ATF is asked to trace a gun’s serial number, it can take a week of rifling through the paperwork to trace the gun. If a gun seller sends in information about sales on a thumb drive, the ATF is required to print out all the data, keep the paper records and destroy the drive.
I spent a large amount of last year rebuilding DocumentCloud. A rebuild is always a risky proposition and carried some serious risks. I thought I'd take a moment to explain why it was the right solution and how we approached it.
In 2023, we added some new features like an improved Add-Ons browser and redesigned some existing components, which created some inconsistency between the old-and-new visual languages. At the same time, we were redeveloping existing components to support TypeScript and improved network handling, implementing modern best practices. The codebase was becoming increasingly fractured as we continuing developing using new methods and technologies.
After building on the existing site through 2023, it became clear that the existing codebase was an obstacle to speedy development. The site ran on a bespoke Svelte SPA framework and state manager. While this was the best solution when the last version was developed in 2018-19, solutions like SvelteKit had since eclipsed it. We were spending as much time working around quirks in the custom frameworks as we were shipping new features. In order to speed up development, we'd either have to invest time in updating the existing framework or replace it.
Early in 2024, Chris Amico created an experimental branch that used SvelteKit as an application framework. Within a few weeks, he had listing and searching working to the point that we could evaluate it against the existing site. A few things immediately stood out: the code was much simpler and the site ran much faster. This was the validation we needed to keep going. Around this time, Chris also index the existing application for all its functionality to understand how much work a rebuild would take.
This approach was aided by DocumenetCloud's decoupled architecture: the backend API runs as a separate service from the frontend application, which itself is the single largest consumer of the API. With this architecture, it meant we were swapping out the UI layer, without worrying about disrupting the core functionality of the service.
By the end of March, we had a functional prototype to share with the rest of the MuckRock team. We demonstrated the gains in speed and simplicity, while sharing the checklist of features to implement. Our next step would be to implement a feature-complete domain within a month. We figured that if we could achieve that next milestone without exceeding an estimated timeframe, then we'd have the confidence to proceed with the rest of the project.
Fortunately we were very successful, reaching that milestone ahead of our deadline. We were already feeling the productivity benefits of switching to SvelteKit, and felt very confident that the rebuild would proceed on schedule. With buy-in from the rest of the team, I charted out the next 5 months of development, focusing on addressing high-risk areas first. These were either the most complex features and functionality, the ones most critical to the application's utility, or the ones where we needed to understand more in order to succeed.
One-by-one, we checked off those high-risk areas until all we were left with was the long checklist of more mundane features: CRUD operations, interface elements, and error handling. Along the way, we would periodically refactor to reflect improved knowledge or evolve the codebase structure.
The last few months were spent winnowing down our open tasks until we successfully launched a beta in early October, which was followed by a wide release. During our beta period, we monitored Sentry for crash reports and issues and checked in on submissions to a free-form feedback form we created. These two solutions—one qualitiative, one quantitative—provided us with strong feedback for where we needed to focus pre-launch.
Now that the new DocumentCloud is live, we've been able to release changes much faster. It means we're now introducing new features and fixing issues raised by our feedback mechanisms. The challenge now is in scaling and optimization, as the DocumentCloud service has millions of visitors a month, and these issues didn't reveal themselves until we had completely migrated to the new version.
While a rebuild is always risky, I think we managed the risk extremely well by continually validating our approach as we iterated towards the final solution. The outcome is now a much simpler, much faster application and a speedier development cycle, both of which let MuckRock more effectively and efficiently serve the millions of DocumentCloud visitors and thousands of newsrooms who rely on the service for their reporting.
Flexoki is a color scheme for prose, developed by Steph Ango, the creator of Obsidian. Ango describes the project:
Flexoki is designed for reading and writing on digital screens. It is inspired by analog inks and warm shades of paper.
I think it looks fantastic, especially in dark mode. The colors are vibrant without being super saturated, and I find their warm tones calming.
This project has been a battle between my competing desires in science and art. One part of my brain searches for reliability and precision, while another part searches for those elusive imperfections that remind us what feels real. Solving for all these problems is how I arrived at Flexoki.
I’ve been thinking recently about whether, and how, software grows patina. Software is self-replicating, the same the first time and the thousandth time it’s run. It’s the imperfections of aging that makes the world feel alive.
Today is the fourth anniversary of the attack on Congress and attempted coup of the United States government and the man who incited it will be sworn in as President of the United States later this month. On this dark day, it is important to remember what happened and why, so I went back and looked at some of what I posted in the aftermath of the attack. Here are a few of the videos, articles, and thoughts worth a second look.
When I imagine electrified transportation with the potential to transform and decarbonize society, I don’t think of electric cars. It’s e-bikes that have the biggest potential for impactful change to how we live.
I’m really excited by the thinking behind CLIP: it’s an intervention that electrifies existing bikes and makes bicycle commuting more accessible. It’s just damn good design.
Yesterday, I linked to a tutorial on Atkinson dithering. I think dithering is an extremely cool effect, especially when trying to achieve a retro aesthetic. Bill Atkinson developed his take on a dithering algorithm for the first Macintosh, and his results are supremely “Mac”—it tends to produce the most (subjectively) pleasant images compared to other methods.
But what’s the appeal of a retro aesthetic, especially when it comes to computers? I’ve been asking myself this question ever since I discovered SRCL, a React component library by INTDEV for building webpages with a retro terminal aesthetic. Let’s be clear, it does look very attractive and cohesive. But, given that you could make the web look like anything, the question remains: what is the appeal to a retro aesthetic? Obviously, nostalgia is at the root of any retro style—an attempt to recreate the past inside the present. What about the computers of the past are we trying to recapture in the present?
My hunch is that were trying to recreate the raw simplicity of vintage systems in order to recapture the trustworthiness and legibility of simpler computers. Presently, most of us are using devices that glued shut and unrepairable. We’re using web-based software that changes out from under us without notice. LLMs and neural networks are more popular than ever, and they are black boxes that produce inexplicable results. Tech has gone from a niche, enthusiast industry to a world-dominating force and a nexus of power.
There is an innocence, a naïveté, and a raw joy that’s invoked by referencing interfaces that predate the mass-adoption of computers and the internet. It’s comforting to think that just by applying a theme, we can relive a simpler time when computers were a novelty, their role in the world was still uncertain, and their impact was gentler. But nostalgia is always for an imagined past. This component system uses React, so the simpler computing mode it re-enacts depends upon bloated computing model that depends on large amounts of memory, fast internet connections, and cheap energy.
Its fun to play pretend, but it’s important to recognize how appeals to nostalgia mask the true nature of things as they are. When high-tech disguises itself as low-tech, you get the worst of both worlds: the excesses of the present and the limitations of the past, muddled together for an aesthetic goal. There are wonderful ways to achieve a low-tech, low-energy, and more sustainable web; but I’m afraid this is just window-dressing.
Yesterday, I mentioned that I've been saving bookmarks with Raindrop. I've been saving bookmarks for over a decade. For me, it's the only sensible way to remember anything I come across online. Effectively, I have created a personal subset of the web. Bookmarking is a better habit than dumping everything to a "read later" queue, since I'm not creating yet another inbox that I need to clear out later.
I switched to Raindrop last year after deciding not to renew my Pinboard subscription. The product is increasingly unstable and under-supported, and I became worried about it disappearing entirely. Dissatisfied at $22/year, I declined to renew my subscription and looked around for alternatives.
Bookmarking is a relatively straightforward problem, so fortunately there's lots of options. Raindrop, a service with apps for macOS and iOS, was the most recommended. After creating my account, I was able to import all of my bookmarks from Pinboard. Raindrop has a generous free tier, so I haven't even signed up for their paid plan. Much like Pinboard, it's the work of a sole developer, so I'm hoping that it won't meet the same fate by 2035.
Here's some links I've recently saved:
HEX is a typography company founded by Nick Sherman. I discovered this through Erin Kissane, who used HEX's MARGO to beautiful effect on their new site, wreckage/salvage.
Womp is a fascinating, browser-only 3D design tool. I haven't tried it out yet, but I bookmarked it to explore later. I discovered this through Dense Discovery, a fanstastic weekly newletter.
I should stop here—I have so many more links to share, and they'd each shine as their own separate post. I even have more to say about each of the links I shared above!
In traditional holiday fashion, I'm dusting off the ol' blog and trying to commit to posting more regularly. Let's see if it sticks this time!
I think I've got a good foundation to at least share a few interesting links each week, since I've got a long backlog of links saved in Raindrop.
I've also got a bunch of interesting work slated for this year, so I'm hoping to use this space to think through problems and share progress in a more public way.
Among those projects, I've got a shortlist of updates I'd like to make to this site. Tagging is top of the list, as well as a saner method of tracking all my notes and highlights. After a few years they've built up into something that's hard to navigate, with inconsistent formatting. I suspect there's lots of software that needs updating, too.
While developing a new application with SvelteKit, I figured I'd go for an off-the-shelf solution for authentication.
I quickly found myself frustrated with Auth.js, since they promote using OAuth provided by big tech companies and discourage credential-based auth. I thought, what the heck, let's try rolling my own auth and see how hard it is.
It's not difficult at all, it just requires a little forethought and care in the implementation. Having gone through this once, I'm not scared of building my own auth solution for projects moving forward. While there are advantages to not rebuilding the same system every time, given how critical authentication is, having control and responsibility for it seems like a worthwhile trade-off.
(If anybody catches an error in how I implemented my authentication system—please tell me!)
Global emissions from burning fossil fuels are projected to rise another 0.8%, for a total 37.4 billion tons (GtCO2), in 2024. Despite growth in fossil emissions, decreases in land-use emissions have plateaued total annual global emissions at 41.6 GtCO2 for the last decade. Atmospheric CO2 is expected to reach 422.5ppm this year.
Among fossil fuels:
carbon is growing but only slightly
oil is growing globally but shrinking in USA and China
natural gas is growing the most, and growing everywhere but the EU
There is some good news:
Emissions from deforestation are decreasing, while reforestation and afforestation are increasing.
Emissions are projected to decrease in the US and EU, with their use of coal-power steadily declining.
Overall, uptake of gas and renewable energy is not fast enough to reverse the growth trend, and there's no sign of a decrease in global total emissions.
Winter Solstice is December 21, 2024 at 4:19AM Eastern. I want to mark it on my digital calendar, Fantastical. Since all the entries are based on events with a duration, there's no way to "bookmark" a specific moment in time and space. Even if I create an event that starts and ends at the same time, it still shows up on my calendar as something with a start and an end, when I really want it to appear like the "now" indicator:
A recent preprint claims terrestrial carbon sinks trapped much less atmospheric CO2 than in previous years. Patrick Greenfield, covering it for The Guardian, reports:
“The issue of natural sinks has never really been thought about properly in political and government fields. It’s been assumed that natural sinks are always going to be with us. The truth is, we don’t really understand them and we don’t think they’re always going to be with us. What happens if the natural sinks, which they’ve previously relied on, stop working because the climate is changing?” says Watson.
Reflecting on living through 2020, I remember just how quickly everything changed. First, a few months of reports of a new SARS in China. Then, a couple of weeks when Seattle nursing homes became infected and US caseloads were in the hundreds. It took less than a week in mid-March for the virus to spread to a point where we collectively recognized lockdown as a necessity. In just days, everything became upended.
The exponential changes within the system are already changing life in a matter of days, if not weeks. We're seeing this in Asheville after a monstrous amount of rainfall. Nobody could imagine this scale of impact—in the mountains, no less—until it was already happening. Witnessing meteorologists grappling with the size and intensity of Hurricane Milton—struggling to communicate the strength of the storm—is a sign of how hard it will be to adapt our thinking to exponentially-worsening circumstances.
8PM EDT: This is nothing short of astronomical. I am at a loss for words to meteorologically describe you the storms small eye and intensity. 897mb pressure with 180 MPH max sustained winds and gusts 200+ MPH. This is now the 4th strongest hurricane ever recorded by pressure on this side of the world. The eye is TINY at nearly 3.8 miles wide. This hurricane is nearing the mathematical limit of what Earth’s atmosphere over this ocean water can produce.
Part of that rapid change will be fed by systems breaking down unexpectedly, instead of remaining in a stable, predictable state. Carbon sinks already aren't behaving like we expected. There's a chance the Gulf Stream could break down. These changes feed one-another, accelerating climate change. We won't have time to adapt. We live precariously.
While reading the release notes for React 19 RC, I was thrilled to see the addition of a new hook, useActionState.
This hook renames useFormState, moves it from the react-dom package to the core react package, and adds an additional return value that indicates the pending status of the returned server action. This hook is critical when writing any code that interacts with Next.js Server Actions.
I was thrilled not just because it's the exact change I suggested the last time I wrote about useFormState, but also because my post was cited in the PR introducing the change! I'm stoked to replace my home-baked solution with this built-in API, and I'll be updating my previous post to point to the new solution.
I owe a proper "thank you" to Ricky Hanlon, who took my feedback and introduced this change. Thanks, Ricky!
Oleksandr Hlushchenko’s release update for FSNotes 6 begins:
Hello everyone, it’s been a long time since the last big issue. The covid ended, the war began, I moved to Lviv, this post I am writing with no light at all. A huge series of events, among which it would seem there is no place for development. But luckily life hasn’t stopped and today I am happy to present you a new major update for macOS, on which I’ve been working since May.
So let’s start with the new features.
Woof. I admire and respect Hlushchenko’s resilience and dedication. I also know how engrossing work can sometimes be a means of escape.
FSNotes is an open source project, so I can see that version 6.0.0 released on October 30, 2022—I can also see that the most recent update, 6.7.1, is just about a month old. While it’s available as a free download, I didn’t hesitate to spend fourteen dollars on it in the iOS and Mac App Stores.
When opening FSNotes for the first time, there’s already some notes pre-loaded in its library. Numbered one through nine, these notes provide an introduction to the software and its functionality. The first note starts off:
Hi, my name is Oleksandr and I am the author of this program. A few years ago, I discovered that my favorite note-taking application, nvALT, no longer starts.
None of the existing alternatives for macOS and iOS suited me, and since I have been developing for many years, I tried to write my own solution. In the summer of 2017, I published the source code of FSNotes on GitHub. It was a terrible application 🤬. Terrible and with poor functionality. But I did not give up and contributors did not either.
At this time, FSNotes is translated into 12 languages and used across the globe. The number of features has exceeded one hundred, of which dozens are unique.
The first thing that made NV great (and nvALT great, too) was how it kept up with you as you typed. It never derailed a train of thought. This stemmed from its modeless design: searching flows naturally into either appending to an existing note or writing a new one. As a user, you’re not interrupted by a decision. After memorizing NV’s keyboard shortcut, you could switch into it mid-sentence. Which is to say, it was like you thinking your way into the software.
The second thing that made NV great was that it was file over app, a phrase coined by Steph Ango. Ango is the developer of Obisidian, another great writing app (calling it a writing app only scratches the surface of its capabilities, but writing is the primary interaction). By Ango’s definition, “File over app is a philosophy: if you want to create digital artifacts that last, they must be files you can control, in formats that are easy to retrieve and read.” NV could be configured to store notes on disk as plain text files (for example, to a folder synced with Dropbox) instead of into a single database. FSNotes saves all its content as files, synced across devices with iCloud Drive. Since all its content is files, FSNotes also supports Git versioning and backups.
While immaterial, applications aren’t immortal. Over time, without care and attention, they can rot. Like a forest cabin or a shingled costal home, software needs continual repair if it has any chance of standing up to the accumulation of changes across OS updates and hardware platforms. This is why, as Ango writes, “in the fullness of time, the files you create are more important than the tools you use to create them. Apps are ephemeral, but your files have a chance to last.” In theory, an NV folder begun over a decade ago could be used by FSNotes today.
Even as computing moves into a world of clouds, apps, and black-boxed neural networks, it’s a relief to know there’s developers like Oleksandr. In the middle of a war, he continues to white software designed to endure. FSNotes is shared openly, with a simple ask for support. It’s based on the filesystem, uses native frameworks, and runs fast (even when loading hundreds of thousands of files). The world would be better off with more developers like him, and more software like FSNotes.
Cory Doctorow’s 2023 essay introducing enshittificationinto the popular lexicon gave a name the vague feeling that the arc of platforms bends towards extracting increasing value from their users at the expense of the experiences that originally grew their usage. Edward Zitron’s report last month on the decline of Google Search gives a name to the individuals directly responsible for it:
“These emails are a stark example of the monstrous growth-at-all-costs mindset that dominates the tech ecosystem, and if you take one thing away from this newsletter, I want it to be the name Prabhakar Raghavan, and an understanding that there are people responsible for the current state of technology.
These emails — which I encourage you to look up — tell a dramatic story about how Google’s finance and advertising teams, led by Raghavan with the blessing of CEO Sundar Pichai, actively worked to make Google worse to make the company more money. This is what I mean when I talk about the Rot Economy — the illogical, product-destroying mindset that turns the products you love into torturous, frustrating quasi-tools that require you to fight the company’s intentions to get the service you want.”
The whole piece is an excellent example of reconstructing a narrative from public records—in this case, internal Google emails released as part of the DOJ’s antitrust investigation. It’s one thing to read Zitron’s story, but another to see the facts written down in presumed confidence by the actors themselves.
I was sitting on my front porch after lunch, about halfway through reading Alex Ross's recent article, "What is Noise?," when my neighbor's hired landscaper began using a leaf-blower. He was using it to clear away bits of mulch that, while being moved and spread, had fallen on the pavement.
A simple broom could have swept clean the mess. A more careful application of the mulch could have avoided spilling any where it didn't belong. The high-decibel noise of the gas-powered compressor exposed the wasteful carelessness of the work done.
In describing how the quality of noise has changed between analog and digital technology, wasteful carelessness is the defining characteristic of the information we're increasingly presented with:
The irony is that the atomized buzz common to so much late-twentieth-century technology—fax machines, dial-up modems, the hiss between stations on a radio dial, the “Poltergeist” snow of a TV left on overnight—has largely faded. Such noise now resides in our minds, as we fend off notifications, updates, “Just for You” suggestions, consumer-feedback requests, obscene spam, clickbait headlines, A.I.-generated news stories, A.I.-generated news stories about A.I., and the whole silently screaming rest of it.
As the costs to publishing anything online continues its march towards absolute zero, noise becomes the marker of Silicon Valley's brute-force attempts towards persuading, targeting, and manipulating. The electricity and water wasted by data-centers computing poorly personalized and mechanically authored information that will only annoy before it's ignored is stupid.
Noise draws attention to the energy wasted by careless effort. Noise is a product of cheap energy, externalized costs, and an absence of professional ethics. Noise can be annoying as hell!
I built a fantastic application layout today. Lightweight, responsive, rock-solid, uncomplicated; it just works. I feel immense satisfaction when I can solve a problem, completely, in the fewest possible steps. It was just a just few hours of work, supported by a few additional hours of sketching and mocking, but possible because of the thousands of hours I’ve spent solving this kind of problem over the last decade.
In the fall I built a compost bin. Having a healthy balance of green (nitrogen-rich) and brown (carbon-rich) compost promotes decomposition; an ideal ratio is about 4 parts brown to 1 part green. One issue I have is that our kitchen and garden compost produces plenty of green matter, in the form of veggie scraps, weeds, and trimmings, but not nearly enough brown matter to balance it out. Fortunately, my neighbor just down the alley is a woodworker, and every week she puts out a garbage bag full of sawdust. After chatting with her, I now have a ready supply of sawdust, which is a wonderful brown compost additive: its small particles have a high surface area, so it decomposes faster and absorbs more moisture from the greens. Now I'm helping my neighbor to divert some of her waste while I'm putting it towards building better soil and, with any luck, growing better vegetables.
[@portabletext/react] Unknown block type "break", specify a component for it in the `components.types` prop
Server actions are the new shiny toy in Reactland, and for good reason: they make handling form submissions more straightforward than they've even been for front-end developers. That being said, they're still in an experimental state, so the APIs for handling them shouldn't be taken for granted.
So far, I've found the useFormStatus hook, as it currently works, to be all but useless. While its intended purpose is to return the form's pending state, this comes with a huge caveat: it only works when called from within a form child. Any examples I can find for its use all copy the React documentation, which disables a submit button. Besides problems in its implementation, its current design is flawed:
Placing a submit <button> outside a form is valid HTML, as long as the button references the form's id. The child-component limitation on useFormStatus makes it harder to progressively enhance a form that works natively using browser defaults.
Requiring the calling component to be a child of a <form> means that any other form elements, like inputs, can't be disabled while the form is submitting unless they're wrapped in their own components. This undoes much of the simplicity gained by using server actions with native HTML forms.
Basically, I avoid useFormStatus entirely in favor of useTransition, which tracks the form action's pending state without blocking other user interactions. Since the transition calls the function provided by useFormState, the formState value updates with the result of the form action.
The only downside is that now forms override their native functionality with an onSubmit handler. But the form will still work without JavaScript enabled since the server action is still being passed to the form's action attribute.
Given how I'm basically wrapping useFormState, I'm very surprised that this API doesn't already provide tracking for the server action's pending state. As these experimental features continue to evolve, I hope the React team takes this feedback under consideration.
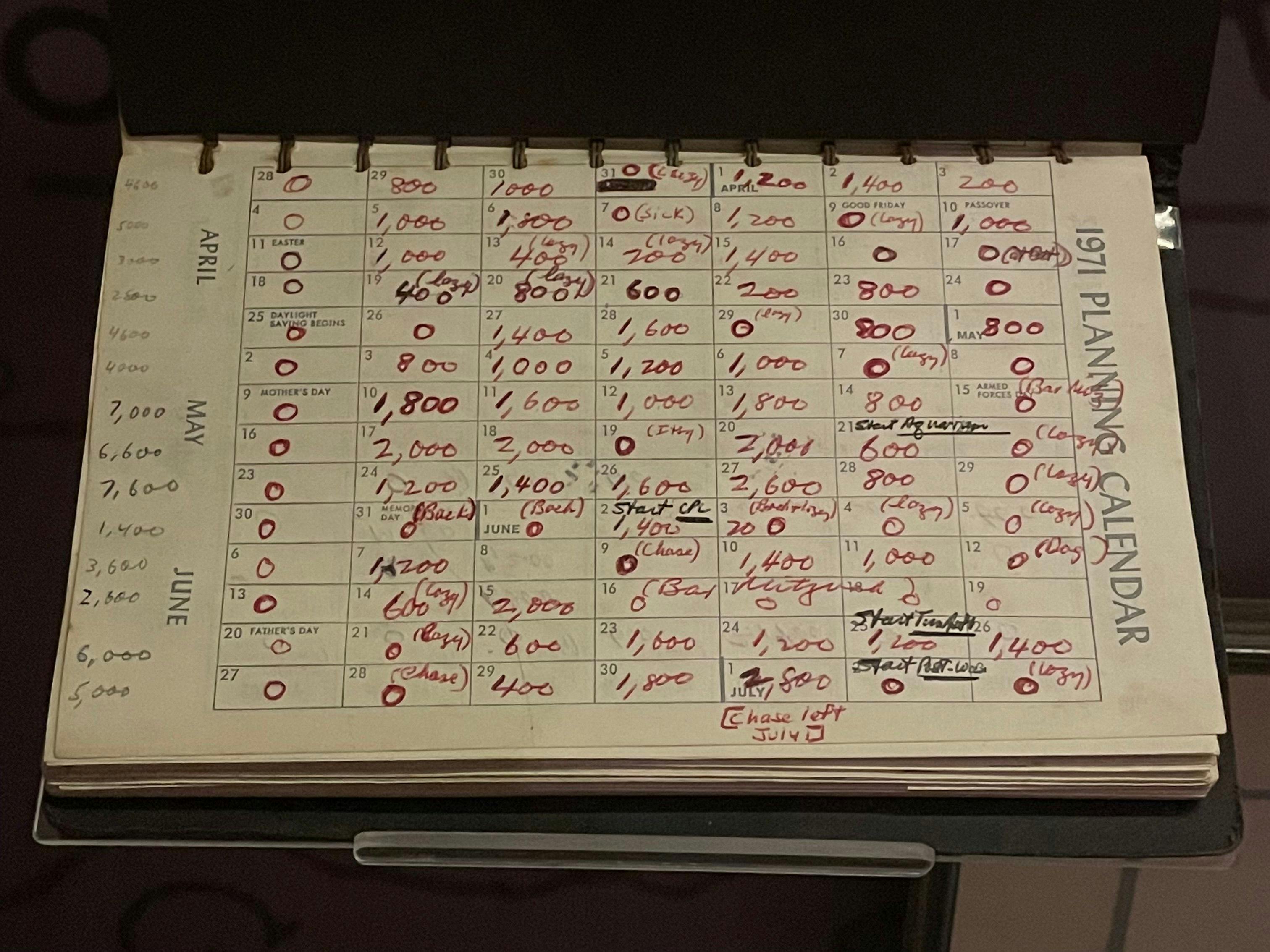
I've been a big fan of Notion for years, since I first learned about it in late 2018. I run my freelancing business on Notion, using it to keep track of all my meeting notes, project details, client directories, task lists, and development timelines.
I've also extended it into my personal life for daily journaling and habit-tracking. A habit tracker is a case study in how Notion databases can be configured to create adaptable, powerful tools. Here's how you can create one, too:
Create a new database. Call it "Journal," "Habits," or whatever else you'd like.
Create a new template for your database. Templates can be created from the menu under the dropdown arrow ⌄ next to the "New" button in the upper right of the database.
In the new template, title it as “@Today,” then select the "Date when duplicated" option. This will set the title of each entry to the date it's created, giving each journal entry a unique title that's easy to find when searching.
Add a "Date" type property. Like with the title, select "Date when duplicated" as its value. This will help with filtering and sorting views to allow you to view entries by day, week, month, or year.
Leave the template editor, then again open the template menu from the dropdown menu next to the "New" button. Open the menu for the “@Today” template you just created by clicking its ••• button. Select "Repeat," then configure the template to repeat daily at whatever time you'd like (I chose 7 AM).
Finally, I set up three views on my database:
a table view that gives me a reverse-chronological list of all my entries, which is great for getting a high-level look at my habit-building progress;
a weekly calendar view;
and a monthly calendar view.
With this, every day a new entry will automatically appear in the database that's automatically set to the date it was created. From here, add new properties to your database for tracking habits. Since each entry also has its own free-form body, this serves as a blank page for a daily journaling habit, as well.
For example, my database has a checkbox property for "Did I exercise today?" Inspired by the word-counting calendar Robert Caro kept while writing The Power Broker, I also keep track the number of words I write each day.
A page from Caro's word-counting diary was exhibited as part of "'Turn Every Page': Inside the Robert A. Caro Archive," which is still on display as of the time I'm writing. Good on Bob for taking Sundays off.
Like I said, this is a great case study for the power and flexibility Notion affords. To me, their stated mission—"to make toolmaking ubiquitous"—continues on the tradition established by the founders of personalcomputing. It's not the perfect tool for every situation, but it's filled so many niches that it's hard to imagine working without it.
I’ve worked remotely since 2017, both as an employee and as a founder. When we all locked down in 2020, I saw everyone thrown into chaotic remote working situations they had no time to prepare for. At that time, nearly two-thirds of employees polled “felt like the cons outweigh the pros” and a third considered quitting altogether. Four years later, remote work is now an intentional choice made by many organizations—but I still hear my friends complain about their continually dysfunctional remote cultures.
I think that’s a shame, since I’ve come to love the benefits of being remote: working wherever and whenever I’m at my most productive and creative. I’m able to collaborate with teams spread across the country, with people living fascinating lives on their own terms, and maintain a healthy balance between my work and my life. The benefits of eliminating a daily commute cannot be understated, either.
When a company doesn’t have a strong remote culture, avoidable stresses and conflicts become inevitable. There’s no training for an office that suddenly shifts from in-person to on-line when managers are learning in realtime along with their employees. The work never stops, either. There’s no chance to regroup and rebuild a remote culture from the ground up. Changing a company’s culture from the grassroots is difficult when you not only need buy-in from managers, but need them to be the ones leading by example.
Here’s what I’ve learned about how to build a positive, functional remote work culture. These lessons cobbled together from personal experience building remote workplaces, informed other remote-first companies like Automattic and 37signals (a note to remote managers: there are books written about this and you should be reading them!). In retrospect, the best time to have have written these down would have been April 2020. But, as the old saying goes, the next best time to have written them down is now.
1. Escalate mode, not tone.
If there’s a golden rule for remote working, it’s this one. There’s a nasty cognitive bias where we read negative emotion into innocuous messages. Like a ship’s crew maintaining their boat against salty seas, workplaces need to be constantly counteracting the corrosive effects of negative intensification bias.
Fortunately, we have the tools to avoid this. As soon as you start to read negative emotion into a text conversation, switch to an audio call. When you switch into a higher-resolution medium, you can hear someone else’s tone, instead of trying to infer it. If a phone call becomes testy, escalate it into video. The more you can see and hear somebody, from audio to video to an in-person meeting, the easier it is to build empathy, resolve problems, and keep your relationship constructive.
This isn’t to say that tension and negativity may be avoided altogether. But if a discussion is on a sour subject, or has the potential to curdle, start it from the highest-resolution medium available and deescalate down from there.
2. Limit communication to specific, enforced hours.
One of the huge upsides of remote work is the flexibility to work when you’re at your most productive. One of the huge downsides is feeling like you’re on-call at all hours of the day. In the US we paradoxically view overwork as an elite signifier; in reality, the overworked are “less efficient and less effective,” more likely to feel depressed and anxious, and experience declines in creativity and judgement. It’s a fallacy to think that working at all hours demonstrates a commitment to success; it only leads to burnout.
Let work happen at any time, but try to limit communication to an agreed-upon window of time. Try to avoid sending emails or messages during this time, and don’t expect any responses if you’re communicating outside that window. Unless one of your specific responsibilities is monitoring resources that need to always be available, the business won’t fail because you waited until tomorrow morning to reply to an email. This is critically true during vacations or holidays when an office is meant to be closed.
A friend of mine here in Indianapolis (Eastern time zone) was just telling me how she works remotely for a company in Portland, Oregon. Her office’s hours are 9am Pacific to 5pm Eastern, which sounds amazing. This policy respects everyone’s schedule while expecting everyone to be available and responsive during the same daily window of time.
3. Use (a)synchronicity to your advantage.
At some point, we’ve all left a meeting with the same feeling: this should have just been an email. In truth, an email isn’t enough, but it can turn an hour meeting into one that’s over in fifteen minutes.
Writing helps articulate your argument, instantly share it, and affords consideration and thoughtful response from readers. Meetings are a great way to synchronously communicate, build consensus, and create opportunities for dialogue and debate. Try to use each to its greatest advantage: don’t introduce new ideas in a call, and don’t expect an immediate response in writing.
Another way to successfully combine writing and meeting could be to speed up a morning stand-up routine. Having everyone write up what they’re working on massively speeds up the process, so that you can focus on discussing blockers and how to overcome them.
4. Don’t backchannel.
Backchannelling fractures and fragments understanding, like looking at your organization through a broken mirror. Nobody is able to see the whole picture, just shards that look different based on their perspective. Keep communication out in the open as much as possible, whether it’s by email, chat, voice, or video. Direct messaging should only be used for “closed-door” situations: providing feedback, expressing concerns, and planning surprise parties.
While it may feel more immediate and secure, these are false positives. It’s no more immediate than sharing the same information in a public. As long as the information being shared isn’t personally private, trust your team to be able to handle it. Tools like Slack and Discord use “channels” to help keep conversations on-topic—channels often provide enough focus to keep the conversation on a need-to-know basis without making it secret, and allowing employees to opt-in to discussions on their own. As you solve problems out in the open, you’ll build build understanding and consensus.
5. Call freely; decline freely.
Talk is cheap. It’s also information dense, synchronous, and empathic. Getting into a habit of simply calling someone when you need to think through a problem can be a powerful force-multiplier. But feeling pressure to answer every call can destroy your focus and productivity. Create an understanding that it’s up to the receiver to answer if they have the time and attention to. If it’s really important, call again. If it can wait, call back or fall back to a more asynchronous mode.
Tools like Discord, Slack, and Teams provide flexible audio/video channels for jumping in and out of quick conversations. The power of a simple phone call shouldn’t be overlooked. Voice memos and voice mails can be easily substituted if you just want to give a quick report. The point is that you’re actually talking to one another like actual human beings, not just typing at one another.
6. Chat is a watercooler. Don’t lean too much on it or things will get messy.
Chat is hard to search, hard to follow, and hugely distracting. It’s a bad format for building shared knowledge and a bad medium for synchronously communicating. When use chat, you let your thoughts guide your speech. Many ideas require more development, more editing, and a slower pace than chat affords. Yet, it’s come to dominate remote workplace culture because it’s so low friction.
Chat works best as a social glue, facilitating low-stakes discussion, scheduling, and sharing for things like quick status updates, dropping interesting links, and sending photos of your pets. Never expect somebody to instantly reply to a DM or a chat, treat it as the lowest-stake mode of communication (see rules ##1, ##3, and ##5). Any important information—a company policy change, or an important deadline—needs to be communicated outside a chat (ideally, as a memo or a meeting, depending on the urgency).
7. Prioritize spending time together, in-person and on-line.
Creating spaces and times to socialize and gather, even through a video call, are essential for building the culture of a remote workplace. Bots that schedule random coffee chats can encourage coworkers to better know one another, while making space in the day for conversation and downtime. Incorporating a creative prompt into a daily stand-up routine can introduce spontaneity into an otherwise rote process. An occasional lunch talk, happy hour or game time can gather everyone for low-stakes, informal hangout (as long as it’s within the office hours established as part of ##2).
8. Managers must lead by example.
This rule applies to the least number of people, but is no less essential. None of these guidelines will work if the people in charge are shooting off 11 p.m. emails that demand an immediate response, feel insecure when their calls go unanswered, and talk shit in DMs. If you’re a manager leading a remote workplace, establish guidelines, follow them yourself, and constructively reenforce them. Managers set the example, reinforce the culture, and have the power to spoil a healthy culture or reboot one that’s crashed.
[@portabletext/react] Unknown block type "break", specify a component for it in the `components.types` prop
Remote working is amazing, as long as its under the right conditions. This isn’t an exhaustive list, and may need to be tweaked and adapted for the particulars of the remote workplace you find yourself in. These principles have, however, helped me to guide frustrating conversations towards constructive outcomes, create a shared sense of purpose, and protected my most precious resource: uninterrupted focus.
Craig Mod's submission to the New York Times's "52 Places to Go in 2024", Yamaguchi, is a spiritual successor to his submission last year, Morioka. In his most recent Ridgeline newsletter, Mod explains why he keeps submitting mid-sized cities with populations in the hundreds of thousands, instead of multi-million metropoli like Kyoto and Tokyo:
Cities like Yamaguchi and Morioka occupy an Other space — an alternative space between the disappearing, somewhat unsustainable, countryside villages, and the non-stop megalopolises. If Kyoto and Kanazawa and Hiroshima are the A-sides of Japan, Yamaguchi and Morioka are B-sides — the side often containing the understated genius of a record. I see a city like Yamaguchi and I think: Good life is possible here, full life, on a human scale, operating within the bounds of a warm community, feeling your own small contributions meaningfully add up in the lives of people around you. When I travel I’m not looking for the most delicious bowl of ramen or the perfect croissant, but rather archetypes of ways of living that set my imagination ablaze, that make me grateful to have encountered those people, and grateful for the social and political infrastructure that exists, allowing these people to live in their own, additive ways.
When I read this, I'm immediately reminded of life in Indianapolis. I've always said it feels more like a big town than a small city. It's just big enough to support the kind of vibrant creative scene that keeps life interesting, with local music, art and food that are worth celebrating. But the city still small enough that those same creative people can make a living doing what they love. What we have here are communities living together, building culture together, and supporting themselves in the process.
Bike Party, May ‘23
Indianapolis is not really a city with "the Nation's best…" anything, and I think that's true for so many Midwest cities that are both beloved by their residents and looked down on by outsiders. It's that feeling of superiority perfectly captured by the Talking Heads's "The Big Country," where David Byrne's character looks down on the country from inside an airplane. The chorus goes, "I wouldn't live there if you paid me / I wouldn't live like that, no siree / I wouldn't do the things the way those people do / I wouldn't live there if you paid me to."
“If you look, the lyrics in the verses are more or less objective—there’s no disdain for the folks down there. It’s pure description; in fact, one could even say it’s sweet and bucolic, which makes the venom of the chorus more surprising (in my view). To me this song is about revealing the irrationality of that venom.”
That venom makes no sense because that kind of distanced observation doesn't tell you much. Places only reveal themselves upon close inspection. It's the same reason why, when people talk about driving across Kansas and Nebraska as "long, flat, and boring," I know they're talking more about their experience inside the car than the landscape they're driving through. Long? Sure. Flat? Mostly. Boring? You're not looking close enough.
If you think the tallest buildings in Kansas are the grain silos, that tells me you've never been to Kansas.
I had to learn this, too. Before I moved to Indianapolis, I had the same opinion of the city as Byrne's narrator: "why in the world would anybody live there?" But staying in any one place long enough means becoming a part of it; and it, of you. The longer the stayed, the more I came to appreciate the culture that's grown up in Indianapolis: WQRT, Kan-Kan, BUTTER, First Fridays, Feast of Lanterns, and on and on.
Indianapolis isn't ranking as of the Best Places to Travel, but that also makes it a pretty damn nice place to live. It's a creative city, but only because it's also modest, affordable, and sustainable. It's one of hundreds of similar mid-sized cities around the world. I love that Craig Mod knows to shine the blinding spotlight of a New York Times feature on a thriving city that lives in the shadows of its neighbor.
Yamaguchi isn't Kyoto, Morioka isn't Tokyo, and Indianapolis isn't Chicago. But it's for exactly that reason that they're worth checking out.
Building my own publishing system has been a fun distraction. This is for better and worse. it keeps my programming skills sharp, but it gets in the way of actually publishing anything. To quote from one of my first notes, "the human condition, the condition of the tool-using animal, is to be perpetually vulnerable to mistaking instruments for ends". I'm as guilty of that as ever.
Anyway, I am about to deploy a new branch that rejiggers my RSS feed. It makes my highlights a second-class data type and elevating the posts I'm actually writing myself. I'm still trying to find the balance for what I want to capture vs. what's truly publishable.
As a result, anyone (anyone?) subscribed to my site's feed may get a big chunk of old posts that will appear unread. It should be a one-time thing, until the next time I decide to flip the table and rebuild my publishing system yet again.
This transcript of Bruce Schneier's lunchtime lecture at the Kennedy School is worth reading in full. He presents a loose case for how and why to regulate the deployment of AI:
In this talk, I am going to make several arguments. One, that there are two different kinds of trust—interpersonal trust and social trust—and that we regularly confuse them. Two, that the confusion will increase with artificial intelligence. We will make a fundamental category error. We will think of AIs as friends when they’re really just services. Three, that the corporations controlling AI systems will take advantage of our confusion to take advantage of us. They will not be trustworthy. And four, that it is the role of government to create trust in society. And therefore, it is their role to create an environment for trustworthy AI. And that means regulation. Not regulating AI, but regulating the organizations that control and use AI.
The ability to access to free, public events like this lunch is one of the things I miss most about living in Boston area.
First, some complaints about automating Apple stuff:
Why are there no Smart Mailboxes or Mail Rules on iOS? Why can't that be synced through iCloud or similar? My rules only get run once I open Mail on my laptop.
The performance of Shortcuts on iOS 17 is terrible and I haven't seen this discussed much. I'm talking like a 5-second delay between touch and response, it's embarrassing.
Creating a Shortcut that makes a HTTP request is pretty challenging. There's no good way to handle errors, so you've just gotta cross your fingers that everything goes 200.
Now, some praise for Apple automations:
Once I've fought Shortcuts and gotten my endpoints working, the ability to fire off arbitrary API requests from my phone is super cool and powerful. I'm writing this in Drafts and publishing it with a Shortcut. That rules!
The ability to compose Shortcuts together means it'll be easier to add new commands that do web stuff, once I have some utilities to handle the nasty bits.
I haven't dipped into Scriptable yet, but it looks really cool. I'm hoping that if I can get out of the mess of the Shortcuts app, I'll be able to work faster by just writing commands with JavaScript.
I just asked an LLM for help writing some AppleScript and—holy moly—it was so much better than trying to write AppleScript myself. Now that I don’t need to learn the syntax, I feel like a world of automation has just opened up to me.
I just recently upgraded my digital garden with search and, like adding feeds, the Next.js App Router made this feature extremely easy to accomplish. But more than a pleasant developer experience, I'm most excited by how simple it was to create a progressively enhanced search interface with React Server Components.
The foundation of the search component is statically-rendered, browser-native HTML that provides a fast, robust, and secure baseline search experience. If you're on a very slow connection, searching the site should be faster than waiting for the interactive JS to finish loading. But, once that JS does load, I can layer interactive affordances on top, like providing instant results as you type and improving navigation.
While this was ultimately a fairly simple exercise, I have a few reasons for sharing the process of developing this component. First, search is a very common pattern and the more documentation on how to build it, the better. Second, this example touches on many new features introduced to React and Next.js while still being simple enough to wrap your head around. Finally, I wanted to share how this framework enables developers to follow a path of progressive enhancement from the very beginning, instead of just shrugging off accessability until "some time later on."
Creating a progressively enhanced search component with Next.js App Router and React Server Components
The first thing I did was create the statically-rendered HTML foundation for this feature. I started by creating some data types, a search function, a <Search /> component, and a new /search page:
importtype{ SearchResponse }from"src/types/search";exportdefaultasyncfunctionsearchFn(
query?:string):Promise<SearchResponse>{if(!query || query.length <2)return{};try{// Provide your own search logic here!return{ results:...}}catch(e){return{ error:String(e)};}}
This search function could do anything—maybe it searches by calling a service like Algolia, or maybe it directly queries a Postgres database. Since the function runs on the server, I'm not risking leaking credentials to the client.
With just this, I already have a fully working search! This relies on the fundamental form functionality provided in every browser. On submission, the form redirects to the search page and provides the query as a URL search parameter. Since the SearchPage is server-rendered, it runs the search and passes the results down to the component without a lick of JavaScript. As a bonus, the search field will be pre-populated with the query string if we refresh the page, or navigate forward or back later.
Now, with this rock-solid foundation in place, I started to progressively enhance the search experience with JavaScript-driven interactions to improve its responsiveness and utility.
Enhancement #1: Instant Search
It's nice getting search results after hitting enter, but it's even nicer to see the results update live as you type.
Since this enhancement has client-side interactivity, I needed to add some asynchronous data fetching behavior and state management inside the component. The simplest way to add this dynamic functionality with React was to encapsulate it as a hook:
src/hooks/useSearch.ts
import{ useCallback, useEffect, useRef, useState }from"react";import{ SearchResponse }from"src/types/search";constSEARCH_DELAY=250;// millisecondsexportinterfaceInitialState{
query?:string;
response?: SearchResponse;}exportfunctionuseSearch(initialState?: InitialState){const[query, setQuery]=useState(initialState?.query ??"");const[response, setResponse]=useState(initialState?.response ??{});const prevQueryRef =useRef<string>(query);const runSearch =useCallback(async()=>{if(query !== prevQueryRef.current){if(!query){setResponse({});}else{try{const fetchRes =awaitfetch(`/api/search?query=${query}`);const searchRes: SearchResponse =await fetchRes.json();setResponse(searchRes);}catch(e){setResponse({ error:String(e)});}}}
prevQueryRef.current = query;},[query]);// Debounce the search so we're not running on every keystrokeuseEffect(()=>{const timeout =setTimeout(runSearch,SEARCH_DELAY);return()=>{clearTimeout(timeout);};},[runSearch]);return{
query,
response,
setQuery,};}
This hook declares the query and response as stateful values, returning them back to the component along with a function to update the query state. It also tracks the value of the previous query with a reference, which will persist the value between component rendering cycles. Finally, it defines a search function and runs it whenever the value of query changes. Finally, the search function runs are debounced to ensure we're not running it responsibly.
Since useEffect can be confusing, it's worth looking closer at how the dependency arrays ensure the search function is run as we expect. The runSearch function is declared with useCallback and a dependency array of [query]. This means that only after the query changes will runSearch be reevaluated with the new query value. Likewise, the effect will only and always run the search function any time the function's value is reevaluated. This dependency chaining means, indirectly, that the effect will run the search function every time the query changes.
It's also worth noting that I'm using a different search function in the hook than the one defined in src/data/search.ts and used by src/app/search/page.tsx. That's because the code in the hook will only ever execute on the client. I always try to avoid making external calls from client code, which risks exposing any API keys or other potentially sensitive information to clients (or, at the very least, risks shipping broken code that cannot access necessary environment variables).
Instead, I took advantage of Route Handlers in Next.js 13 to create a new endpoint to mediate between the client component and the data logic.
Compared to the component I first created, this one:
Declares "use client" at the top of the file, identifying it to Next as a client component.
Assumes the initial data it receives is the same as the initial state of useSearch.
Uses the stateful values of query and response provided by the hook instead of the ones directly passed to the component.
Makes the search field a controlled component by locking its value to the stateful query value; to update the value, I added a function that updates the state whenever the field emits an onChange event.
The Search component will still work without JavaScript, but now when JavaScript is available it will be able to return results immediately. Of course, this behavior could be further customized. It could instead show search suggestions for a type-ahead experience, or prefetch result data without rendering it until the form is submitted.
Enhancement #2: Navigation
Speaking of form submission: by relying on basic browser behavior, the form will automatically redirects to the /search page upon submission. Without changing anything, this would run the query on the server and render a new page with the results.
But, since Next.js provides client-side routing, I wanted to make this interaction even smoother for users who've loaded JS. By handling the form's onSubmit event, I upgraded the form behavior to prefer client-side routing when it's available.
It's helpful to have the query preserved in the navigation history, so that if I choose a result and then use the browser's "back" button, I'm returned to the same search I just preformed. But when using the enhanced instant search, the query isn't preserved in the history.
This was an easy fix. I added a line to the hook's search function to update the route after the search completes. While I was at it, I consolidated my onChange and onSubmit handlers into the hook. Now my hook provides everything the enhanced component needs, without concerning the component with any underlying state management.
(I opted to update the search param during search, rather than on every change to the query value, to avoid adding unhelpful noise into a visitor's browser history.)
By the end of this process, I had only added around 250 lines of code across six files:
A type declaration file (which could have been inlined elsewhere).
A data handling file, to keep sensitive logic isolated from components.
A server component that works without any JavaScript enhancement, which was then upgraded to a client component when enhancements were layered on.
A hook that provides all the enhanced client-side search functionality (which, again, could have been inlined alongside the client component).
A user-facing /search page to render the component and load results, which also statically generates results pages for users without JavaScript.
A /api/search route handler to allow my client-side functionality to safely call my data handling function.
Over half of this was in service of enhanced client-side functionality, which while totally optional, was very easy to include.
Progressive enhancement is a process, not only an outcome
In my experience, when a software company promises to improve the accessibility or compatibility of a feature at a later time, that promise almost never come true. It's understandable why that's the case. There's always new demands and higher priorities that are unforeseeable from the start.
That's why it's important for web developers to use the technologies and strategies that make progressive enhancement part of the development process from the outset. That's also why I'm so excited by the continued development of Next.js and React to make it easier than ever to develop and deploy progressively enhanced frontends.
With Next App Router and React Server Components, I had the framework to easily develop and render static HTML that quickly achieved fundamental functionality. That provided me the foundation to layer on richer functionality for an improved experience. Progressive enhancement was part of the development process from the get-go, leading to a component that works for everybody, all the time.
Since I’ve started collecting notes and highlights here, I’ve been meaning to return them as formatted feeds, RSS being the main one. Well, I got around to it. It was way easier than I remembered, and I even got bonus Atom and JSON feeds out of it.
I’m using Next 13.2 and its new App Directory to generate the site, so this made feeds delightfully simple to implement. In fact, it may be the best experience I’ve ever had for developing content feeds like these. I want to share my walkthrough and results since this is a pretty common task when setting up a new project with Next, and all the existing examples were based in Next’s older pages generation system.
How to Generate RSS, Atom, and JSON Feeds with Markdown content using Next.js App Directory Route Handlers
I started from the point of already having data-fetching functions for getting all my notes from my CMS (the aptly named getAllNotes and getNoteTitle).
When adding a new function to generate the feed, it simply has to set the top-level properties then run over the notes to add them as entries. I author and store all my notes as Markdown, so for each note I render its body into HTML. Each feed format then gets its own Route Handler, which calls the generator function for the formatted feed. Finally, I update the top-level metadata to include links to the newly added feeds.
Create a Site URL
I quickly realized I needed a little utility function to get the canonical site URL. Since I build and host using Vercel, I want to make sure my site URL corresponds with its preview deploy URL. I used a combination of environment variables to figure that out, using a dedicated SITE_URL variable with Vercel’s system environment variables to figure out the build’s context and dedicated URL.
With other site generation frameworks I’ve used, generating feeds has meant writing a template XML file and filling in dynamic values with curly-braced variables, usually with that format’s spec open alongside. This time, I was able to use the feed package for all the XML authoring. As a result, generating multiple feed formats became a matter of making a function call.
The generateFeed function is based on an example provided by Ashlee M Boyer. It creates a feed with proper metadata, then generates each post. Since the Markdown generation runs asynchronously, adding entries needs to happen inside a Promise.all call. This way, generateFeed waits to return the feed object until all content has finished generating.
Now here comes the fun part. Creating feed endpoints becomes so simple it’s silly. Using Route Handlers introduced in Next.js 13.2, adding a new endpoint is as simple as creating a folder in the App Directory with the name of the feed file, then creating a route.ts file inside it.
So, to add the RSS feed, I create the folder src/app/feeds/rss.xml and then create route.ts inside it.
To create the Atom and JSON feeds, I follow the same process ensuring that the appropriate method and content type are used in the format’s route handler.
The last step is updating the site’s <head> to reference these feeds to make them more discoverable to readers. This is made even easier using the App Directory’s Metadata API—also new to Next.js 13.2. In the top-most page or layout file in my app directory, I add an alternates property to the exported metadata object:
Now after running next dev, I can see I have feed files generated at /feeds/rss.xml, /feeds/atom.xml, and /feeds/feed.json. I’ve gotten feeds in three different formats with only a few libraries and simple, easily testable functions.
After deploying to production, you can now follow my new notes via:
The level of productivity I feel when using Next.js, Vercel, and GitHub together is really hard to beat. It feels like the tools are getting out of my way and letting me developer smaller PRs faster.
I’m still a daily RSS user. It’s my preferred way to read on the web. I’m glad to see that there’s still robust library support for RSS and feed generation, at least within the Node ecosystem at least. I don’t think RSS is going anywhere, especially since it powers the entire podcasting ecosystem. It’s great to see the longevity of these open standards.
Speaking of open standards, integrating an ActivityPub server into a Next.js application is something I’m interested in exploring next. It’d be very cool to have a site generated out of an aggregation of one’s own ActivityPub feeds, for example combinining posts from personal micro.blog, Mastodon and Pixelfed into a single syndicated feed.
Seeing all of the recent progress in decentralizing important services has felt so cool. We can still keep the Web wild and weird, empower individuals with more tools for expressing themselves online, and have it all be user-friendly. Content feeds are an important force for good here, so I’m very glad how easy it is these days for even a novice developer to publish them.
I think I’m so smitten by this story — with its mix of deep curiosity into seemingly pointless subjects, followed by the discovery that this “pointless” material is wildly useful in a new domain — because it dovetails with my interest in “rewilding” one’s attention.
I’ve written a bunch about “rewilding” (essays here), which is basically the art of reclaiming one’s attention from all the forces that are trying to get you to obsess over the same stuff that millions of other people are obsessing over. Mass media tries to corral your attention this way; so do the sorting-for-popularity algorithms of social media.
Now, sometimes that’s good! It’s obviously valuable, and socially and politically responsible, to know what’s going on in the world. But our media and technological environment encourages endless perseveration on The Hot Topic of Today, in a way that can be kind of deadening intellectually and spiritually. It is, as I’ve written, a bit like “monocropping” your attention. And so I’ve been arguing that it’s good to gently fight this monocropping — by actively hunting around and foraging for stuff to look at, read, and see that’s far afield, quirkier, and more niche.
This “rewilding” is the same sort of shift in attention away from commercial platforms that Jenny Odell argues for in her book. She uses the exact same analogy to “monocropping”:
It’s important for me to link my critique of the attention economy to the promise of bioregional awareness because believe that capitalism, colonialist thinking, loneliness, and an abusive stance toward the environment all coproduce one another. It’s also important because of the parallels between what the economy does to an ecological system and what the attention economy does to our attention. In both cases, there’s a tendency toward an aggressive monoculture, where those components that are seen as “not useful” and which cannot be appropriated (by loggers or by Facebook) are the first to go.
A monoculture is an illuminating frame for considering attention. Created in an attempt to achieve economies of scale, monocultures reduce biodiversity and exhaust their soil. To make up for this, they’re covered in heavy amounts of fertilizer and pesticide to maintain their productivity. The analogs to commercial social media are clear. Whether they’re lying about their metrics, unfairly compensating their creators, or simply moderating your timelines without explanation or accountability, commercial social media companies create toxic social conditions in order to establish themselves as places for huge numbers of people to sink their attention. Once they have it, they turn the screws to maximize value for their owners despite the damage it does to their ecosystems.
In resisting this monoculture, I think Thompson misses a helpful middle-ground between a monocrop and a wilderness. In-between lies a garden: small-scale, intentional, low-impact cultivation of attention. A great garden takes time to establish, but once it does it can live by itself, supported by its rich diversity and interdependency.
When I think about the ways I focus my attention, I’ve already established a few gardens. My library of books. My collection of RSS feeds. My relationships. My actual garden! All of these contribute to a diverse, interconnected space of shared ideas that help me understand and appreciate the world in new ways.
I want my website/homepage to give me ways to keep track of bookmarks, notes and highlights in the things that I’m reading. I’m typically creating these on my phone or tablet, and the kind of data varies with the kind of reading:
when browsing the web, I’m saving tagged bookmarks into Pinboard. This is like my private search engine, where it’s easy to recall things I have seen in the past that I wanted to remember.
when reading on my phone or tablet, it’s usually RSS or Instapaper–in that case, I’m typically highlighting passages and marking posts as favorites. I want to be capturing my highlights and favs as content in Sanity.
I don’t typically read books on computer, but I also want to be capturing highlights and tracking favs as content in Sanity.
Seems like we have a system starting to come together:
bookmarks can continue living in Pinboard, and I can provide a way to browse and search these on my personal site.
I have the same workflow triggers for my reading. I want to save favorite articles or books into Sanity, and I want to capture highlights or reading notes on those entities.
Are a highlight and a note the same? I think so, because they’re both text. That text could be anchored to a page or other location, but it’s all just text content at the end of the day. I think I would want to create multiple entries, with one for each note/highlight. This also allows for a note to be combined with a highlight if a passage triggers a thought.
This is exactly the same kind of Markdown I’d be capturing in Drafts. I could easily turn this into a JSON payload and send it off.
Since I’m starting from a place where I’m capturing notes, it makes sense that notes would have an association with a source. The source could be a web article, a book, a movie, anything really. I could put a type field on sources to distinguish between mediums, if necessary. I could also pretty easily generate a citation for each note if I know the page and the source!
If I’m capturing a note on a web article, I’m probably going to need to create the source at the same time that I create the note. If I’m reading a book, there’s a good chance that I’ll need to find an existing source for the note.
At the time I’m creating a note, there’s two ways that I will be associating it with a source. I will either need to be creating the source at the same time, or I’ll need to find an existing source.
This workflow suggests that I’ll want to:
Capture the highlight and create a draft entry in Sanity
Get the URL for the newly created entry, then open its page in the browser
From there, I can associate the newly created note with a source and publish it.
I also want to be able to create a source from a URL or from an ISBN. This is a convenience feature and can come later!